SETS 2018

South European Test Seminar |
February 19 - 23, 2018 |
The South European Test Seminar (SETS) is a forum dedicated to presenting and discussing scientific results, emerging ideas, practical applications,
hot topics, and new trends in the area of electronic-based circuit and system testing.
In 2018, SETS is organized by the University of Bremen / DFKI GmbH, Bremen, Germany.
SETS 2018 will take place in the hotel "Alpenhaus Kaprun" in Kaprun, Austria.
The technical program includes (but is not restricted to) the following topics:
In 2018, SETS is organized by the University of Bremen / DFKI GmbH, Bremen, Germany.
SETS 2018 will take place in the hotel "Alpenhaus Kaprun" in Kaprun, Austria.
The technical program includes (but is not restricted to) the following topics:
Analog, Mixed-Signal, RF Testing
Automatic Test Generation
Fault Simulation / Emulation
Low Power Design
Test Data Compression
Built-In Self-Test (BIST)
System-On-Chip (SOC) Test
High-Speed I/O Test
Memory Test and Repair
Microsystems / MEMS Test
2.5D, 3D and SiP Test
Design for Reliability
Power Issues in Test and Fault
Tolerance
Fault Diagnosis
Design For Testability (DFT)
System-in-Package Test
Design Verification/Validation
Online Test Error Correction
Hardware Security
Test of Secure Devices
Trust Issues in Test
 Kaprun is located in the Pinzgau District, the most mountainous district of the Salzburger Land. The "Innergebirg", the south of the Salzburger Land,
is characterised by distinct mountain ranges, the rugged Steinberge Mountains and the white, glaciated 3.000 metres high mountains of the Hohe Tauern.
Kaprun is located in the Pinzgau District, the most mountainous district of the Salzburger Land. The "Innergebirg", the south of the Salzburger Land,
is characterised by distinct mountain ranges, the rugged Steinberge Mountains and the white, glaciated 3.000 metres high mountains of the Hohe Tauern. The 4 star seminar and wellness hotel Alpenhaus Kaprun stands right in the centre
of Kaprun, very close to the Kitzsteinhorn glacier. The nearby glacier
ski area on the Kitzsteinhorn is easily reached by ski bus or a drive of just a few minutes. The Gletscherjet or the Panoramabahn whisk you comfortably
up almost 2000 m, and further modern lifts take you up to a height of 3000 m.
The 4 star seminar and wellness hotel Alpenhaus Kaprun stands right in the centre
of Kaprun, very close to the Kitzsteinhorn glacier. The nearby glacier
ski area on the Kitzsteinhorn is easily reached by ski bus or a drive of just a few minutes. The Gletscherjet or the Panoramabahn whisk you comfortably
up almost 2000 m, and further modern lifts take you up to a height of 3000 m.Apart from that, The Maiskogel family ski area in Kaprun is just a walk of a few minutes from the hotel. The Panoramabahn lift takes you up the mountain to their skiing pleasure on the Maiskogel. For beginners, the Lechnerberg in Kaprun is similarly easily accessible on foot.
» Get an overview of the skiing possibilities and prices for ski passes
The program of SETS 2018 can be downloaded here.
Aim and Scope: The aim of the seminar is to bring together Ph.D. students and researchers from universities and companies to establish a forum for discussion and presenting the latest research results. Topics include, but are not restricted to the following:

Aim and Scope: The aim of the seminar is to bring together Ph.D. students and researchers from universities and companies to establish a forum for discussion and presenting the latest research results. Topics include, but are not restricted to the following:
- Faster-than-at-Speed-Test
- Low-Power, AMS & Defect-Oriented Test
- Design Security
- Online Fault Diagnosis & Self-Verification
- Design for Reliability & Fault Tolerance
- Security in Test & Scan Architecture
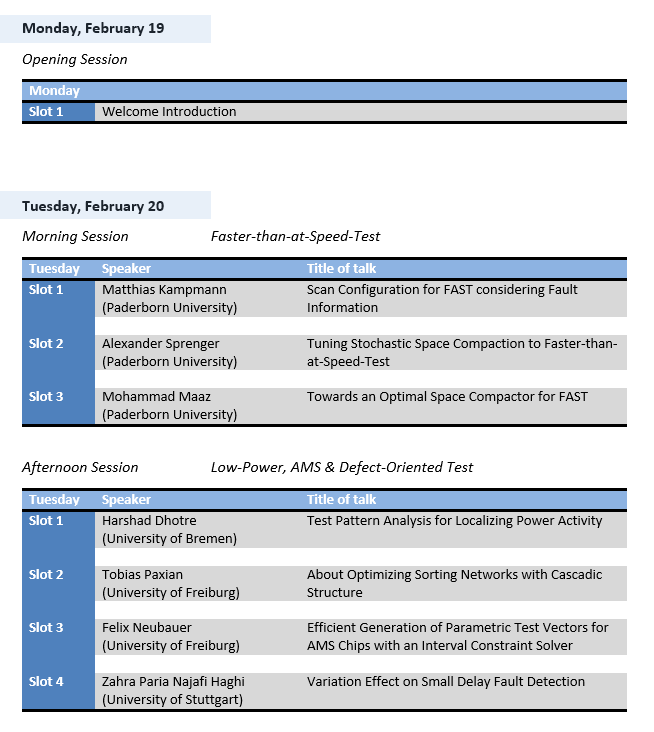
1. Topic: Faster-than-at-Speed-Test
Matthias Kampmann (Paderborn University)
Scan Configuration for FAST considering Fault Information
Modern technology nodes not only enable higher performance at reduced power consumption, but they also are more susceptible to process variations and Small Delay Defects (SDDs). These defects can hint at an impending early life failure of the device, making SDD detection critical for high-reliability applications. Faster-than-at-Speed Test (FAST) allows for detecting even very small, unexpected additional delays by applying the test patterns at clock speeds above the rated speed of the device. However, sampling outputs at earlier observation times than intended by the system designer can cause some outputs to violate the target timing. In such a case, the output value cannot be reliably determined by simulation, making it unknown. Unknown logic values (X-values) are challenging during test response compaction, making the support for X-tolerant compaction a necessary addition to the FAST framework, as FAST produces a significantly larger amount of X-values than conventional or at-Speed delay tests. Recently, the "Design-for-FAST" architecture has been proposed. In it, Scan-Flip-Flops (SFFs) are clustered with respect to their X-Profile, i.e. when and how often the individual SFFs are expected to capture X- values. This allows grouping SFFs with similar X-profiles into the same scan-chain, significantly increasing the efficiency of very simple masking schemes.
However, the graph-based SFF clustering scheme presented in previous publications does not consider fault information during clustering, which can negatively impact the test pattern count required to reach a target fault coverage. The approach presented in this talk tries to solve this problem by introducing firstly an enhanced topological distance function which considers the topological path lengths not only at a target observation time, but at a slightly earlier observation time as well, thus increasing the efficiency of the generated SFF clusters. Secondly, the problem at hand is interpreted as a classic partitioning problem, which is consequently solved by applying the Simulated Annealing metaheuristic. A new cost function is proposed which takes both the X-profiles and fault information into account. By using custom weights, a trade-off between X-masking effectiveness and fault efficiency can be made as the user desires. Simulation results are presented that show the effectiveness of the proposed approach in comparison with existing SFF clustering algorithms.
Alexander Sprenger (Paderborn University)
Tuning Stochastic Space Compaction to Faster-than-At-Speed Test
Small delay faults on short paths may be undetectable even during at-speed test. Faster-than-at-speed test (FAST) targets these hidden delay faults by overclocking the circuit, typically using several different test frequencies. Due to the shorter clock periods, the output values on long paths may not stabilize fast enough, and the resulting unknown values (X-values) aggravate test response compaction. As the number and the distribution of X-values vary with the test frequency, X-handling for FAST must be very flexible. Most of the state-of-the-art approaches for X-tolerant test response compaction are not designed for varying X-profiles. Yet, the stochastic compactor by Mitra et al. offers an easily programmable solution, as the compaction logic is controlled by weighted pseudo-random signals. An optimal setup, however, cannot be guaranteed in a FAST scenario. To better adapt the scheme to FAST, the compactor is partitioned into several smaller compactors and the scan outputs are properly assigned to compactor inputs. Finding the best setup then corresponds to a clustering problem, for which several algorithms are presented. Experimental results show that the number of X-values at the compactor outputs can be significantly reduced while maintaining the fault efficiency.
Mohammad Maaz (Paderborn University)
Towards an optimal space compactor for FAST
Testing chips using faster-than-at-speed-test (FAST) can reveal defects that may not be visible with at-speed tests. The hidden small delay defects can become visible at higher frequencies and expose the likelihood of early life failures. However, as the circuit-under-test (CUT) is tested at higher frequencies, many signals may not have stabilized and can lead to unknown responses (X-values). As the test responses are compacted, these X-values can corrupt fault information and lead to significant drop in fault coverage. FAST results in a large number of X-values, particularly at higher frequencies, that may completely corrupt test responses during compaction schemes such as a multiple input shift register (MISR). X-tolerant compaction schemes have been proposed in the past but are not feasible for the large number of X-values associated with FAST. To develop an X-reducing compaction scheme, the FAST responses for each CUT are studied and possible mergers of scan chains are explored. The goal is to stack X-values together to reduce the total number of X-values in the response. This is achieved through an XOR merger of two (or more) scan chains without losing too much fault information in the process. Scan chains with X-values at similar positions are good candidates for merging, however, if a bit carrying fault information is stacked with an X-value, all fault information from that bit is lost. Some loss of fault information may also occur through aliasing where two bits carrying similar fault information are stacked together. The scan chain candidates for merging also depend upon the scan chain configuration. While the current scheme does not remove the X-values completely, it does reduce the number of X-values in the test response and offers space compaction with minimal loss in fault information and small overhead.
Scan Configuration for FAST considering Fault Information
Modern technology nodes not only enable higher performance at reduced power consumption, but they also are more susceptible to process variations and Small Delay Defects (SDDs). These defects can hint at an impending early life failure of the device, making SDD detection critical for high-reliability applications. Faster-than-at-Speed Test (FAST) allows for detecting even very small, unexpected additional delays by applying the test patterns at clock speeds above the rated speed of the device. However, sampling outputs at earlier observation times than intended by the system designer can cause some outputs to violate the target timing. In such a case, the output value cannot be reliably determined by simulation, making it unknown. Unknown logic values (X-values) are challenging during test response compaction, making the support for X-tolerant compaction a necessary addition to the FAST framework, as FAST produces a significantly larger amount of X-values than conventional or at-Speed delay tests. Recently, the "Design-for-FAST" architecture has been proposed. In it, Scan-Flip-Flops (SFFs) are clustered with respect to their X-Profile, i.e. when and how often the individual SFFs are expected to capture X- values. This allows grouping SFFs with similar X-profiles into the same scan-chain, significantly increasing the efficiency of very simple masking schemes.
However, the graph-based SFF clustering scheme presented in previous publications does not consider fault information during clustering, which can negatively impact the test pattern count required to reach a target fault coverage. The approach presented in this talk tries to solve this problem by introducing firstly an enhanced topological distance function which considers the topological path lengths not only at a target observation time, but at a slightly earlier observation time as well, thus increasing the efficiency of the generated SFF clusters. Secondly, the problem at hand is interpreted as a classic partitioning problem, which is consequently solved by applying the Simulated Annealing metaheuristic. A new cost function is proposed which takes both the X-profiles and fault information into account. By using custom weights, a trade-off between X-masking effectiveness and fault efficiency can be made as the user desires. Simulation results are presented that show the effectiveness of the proposed approach in comparison with existing SFF clustering algorithms.
Alexander Sprenger (Paderborn University)
Tuning Stochastic Space Compaction to Faster-than-At-Speed Test
Small delay faults on short paths may be undetectable even during at-speed test. Faster-than-at-speed test (FAST) targets these hidden delay faults by overclocking the circuit, typically using several different test frequencies. Due to the shorter clock periods, the output values on long paths may not stabilize fast enough, and the resulting unknown values (X-values) aggravate test response compaction. As the number and the distribution of X-values vary with the test frequency, X-handling for FAST must be very flexible. Most of the state-of-the-art approaches for X-tolerant test response compaction are not designed for varying X-profiles. Yet, the stochastic compactor by Mitra et al. offers an easily programmable solution, as the compaction logic is controlled by weighted pseudo-random signals. An optimal setup, however, cannot be guaranteed in a FAST scenario. To better adapt the scheme to FAST, the compactor is partitioned into several smaller compactors and the scan outputs are properly assigned to compactor inputs. Finding the best setup then corresponds to a clustering problem, for which several algorithms are presented. Experimental results show that the number of X-values at the compactor outputs can be significantly reduced while maintaining the fault efficiency.
Mohammad Maaz (Paderborn University)
Towards an optimal space compactor for FAST
Testing chips using faster-than-at-speed-test (FAST) can reveal defects that may not be visible with at-speed tests. The hidden small delay defects can become visible at higher frequencies and expose the likelihood of early life failures. However, as the circuit-under-test (CUT) is tested at higher frequencies, many signals may not have stabilized and can lead to unknown responses (X-values). As the test responses are compacted, these X-values can corrupt fault information and lead to significant drop in fault coverage. FAST results in a large number of X-values, particularly at higher frequencies, that may completely corrupt test responses during compaction schemes such as a multiple input shift register (MISR). X-tolerant compaction schemes have been proposed in the past but are not feasible for the large number of X-values associated with FAST. To develop an X-reducing compaction scheme, the FAST responses for each CUT are studied and possible mergers of scan chains are explored. The goal is to stack X-values together to reduce the total number of X-values in the response. This is achieved through an XOR merger of two (or more) scan chains without losing too much fault information in the process. Scan chains with X-values at similar positions are good candidates for merging, however, if a bit carrying fault information is stacked with an X-value, all fault information from that bit is lost. Some loss of fault information may also occur through aliasing where two bits carrying similar fault information are stacked together. The scan chain candidates for merging also depend upon the scan chain configuration. While the current scheme does not remove the X-values completely, it does reduce the number of X-values in the test response and offers space compaction with minimal loss in fault information and small overhead.
2. Topic: Low-Power, AMS & Defect-Oriented Test
Harshad Dhotre (University of Bremen)
Test Pattern Analysis for Localizing Power Activity
The identification of power-risky test patterns is a crucial task in the design phase of digital circuits. Excessive test power could lead to test failures due to IR-drop, noise, etc. This has to be avoided to prevent yield loss and chip damages. However, the accurate power simulation of all test patterns to identify power-risky patterns as well as to find critical areas within each pattern is not possible due to run time and resource constraints. An important task is therefore the selection of a subset of potentially power-risky patterns, which will be simulated in an accurate manner. We propose an independent test pattern analysis methodology for the integration into an existing industrial design flow. The proposed test pattern analysis technique is a lightweight method based on the cell's Transient Power Activity (TPA) to identify potentially power-risky patterns. The method uses layout and power information to identify critical power activity areas using machine learning techniques. Experiments were performed on opensource benchmarks as well as on an industrial design. The results were correlated with commercial power and IR-drop simulation tools. The proposed methodology was found to be effective in terms of speed and localization of the critical areas for unsafe patterns.
Tobias Paxian (University of Freiburg)
About Optimizing Sorting Networks with Cascadic Structure
Optimization problems are common in many disciplines and domains. To solve them, we have to find solutions which are (near-) optimal with respect to user given optimization goals. This can be done with a weighted MaxSAT solver, an extension of SAT solver processing the boolean satisfiability problem (SAT). We therefore developed a new cascadic encoding which breaks weighted MaxSAT down to an incremental SAT problem. To consider all possible weight combinations it uses the sorting network totalizer to find the solution.
We applied our cascadic weighted MaxSAT solver to maximize or minimize switching activities in circuits by mapping them to an optimization function. This significantly improved the number of solved instances compared with the originally used approach.
Felix Neubauer (University of Freiburg)
Efficient Generation of Parametric Test Vectors for AMS Chips with an Interval Constraint Solver
The characterization of analog-mixed signal (AMS) silicon requires a large set of patterns able to examine the parametric operational space without stressing the circuit beyond its working limits. Due to the highly non-linear behaviour of AMS circuits, uncovered parameter areas may lead to inaccuracies during characterization, potentially deteriorating product quality.
We present a method to efficiently create a set of input vectors to cover such a constrained search space with a user-defined density. First, an initial set of patterns is generated using quasirandom Sobol sequences. Secondly, we analyse the patterns to identify and fill uncovered areas in the parameter space using the in-house interval constraint solver iSAT3.
The applicability of the method is demonstrated by experimental results on a 19-dimensional search space using a realistic set of constraints.
Zahra Paria Najafi Haghi (University of Stuttgart)
Variation Effect on Small Delay Fault Detection
Nanoscale technologies nowaday allow for the integration of billions of transistors with feature sizes of 14 nm or below into a single chip. This enables innovative approaches and solutions in many application domains, but it also comes along with fundamental challenges. As devices work properly in the beginning, weak structures must be identified by analyzing the non-functional circuit behavior with the help of appropriate observables. Besides power consumption, the circuit timing is one of the most important reliability indicators. In particular, small delay faults may indicate marginal hardware that can degrade further under stress. However, they can be "hidden" at nominal frequency. Therefore, conventional approaches for testing reach their limitations. In this work, new methods to detect SDDs will be investigated. The effect of process variation specifically temperature, on SDD detection will be discussed. This effect can be used as making the system testing more robust or even take the fault coverage to a higher level.
Test Pattern Analysis for Localizing Power Activity
The identification of power-risky test patterns is a crucial task in the design phase of digital circuits. Excessive test power could lead to test failures due to IR-drop, noise, etc. This has to be avoided to prevent yield loss and chip damages. However, the accurate power simulation of all test patterns to identify power-risky patterns as well as to find critical areas within each pattern is not possible due to run time and resource constraints. An important task is therefore the selection of a subset of potentially power-risky patterns, which will be simulated in an accurate manner. We propose an independent test pattern analysis methodology for the integration into an existing industrial design flow. The proposed test pattern analysis technique is a lightweight method based on the cell's Transient Power Activity (TPA) to identify potentially power-risky patterns. The method uses layout and power information to identify critical power activity areas using machine learning techniques. Experiments were performed on opensource benchmarks as well as on an industrial design. The results were correlated with commercial power and IR-drop simulation tools. The proposed methodology was found to be effective in terms of speed and localization of the critical areas for unsafe patterns.
Tobias Paxian (University of Freiburg)
About Optimizing Sorting Networks with Cascadic Structure
Optimization problems are common in many disciplines and domains. To solve them, we have to find solutions which are (near-) optimal with respect to user given optimization goals. This can be done with a weighted MaxSAT solver, an extension of SAT solver processing the boolean satisfiability problem (SAT). We therefore developed a new cascadic encoding which breaks weighted MaxSAT down to an incremental SAT problem. To consider all possible weight combinations it uses the sorting network totalizer to find the solution.
We applied our cascadic weighted MaxSAT solver to maximize or minimize switching activities in circuits by mapping them to an optimization function. This significantly improved the number of solved instances compared with the originally used approach.
Felix Neubauer (University of Freiburg)
Efficient Generation of Parametric Test Vectors for AMS Chips with an Interval Constraint Solver
The characterization of analog-mixed signal (AMS) silicon requires a large set of patterns able to examine the parametric operational space without stressing the circuit beyond its working limits. Due to the highly non-linear behaviour of AMS circuits, uncovered parameter areas may lead to inaccuracies during characterization, potentially deteriorating product quality.
We present a method to efficiently create a set of input vectors to cover such a constrained search space with a user-defined density. First, an initial set of patterns is generated using quasirandom Sobol sequences. Secondly, we analyse the patterns to identify and fill uncovered areas in the parameter space using the in-house interval constraint solver iSAT3.
The applicability of the method is demonstrated by experimental results on a 19-dimensional search space using a realistic set of constraints.
Zahra Paria Najafi Haghi (University of Stuttgart)
Variation Effect on Small Delay Fault Detection
Nanoscale technologies nowaday allow for the integration of billions of transistors with feature sizes of 14 nm or below into a single chip. This enables innovative approaches and solutions in many application domains, but it also comes along with fundamental challenges. As devices work properly in the beginning, weak structures must be identified by analyzing the non-functional circuit behavior with the help of appropriate observables. Besides power consumption, the circuit timing is one of the most important reliability indicators. In particular, small delay faults may indicate marginal hardware that can degrade further under stress. However, they can be "hidden" at nominal frequency. Therefore, conventional approaches for testing reach their limitations. In this work, new methods to detect SDDs will be investigated. The effect of process variation specifically temperature, on SDD detection will be discussed. This effect can be used as making the system testing more robust or even take the fault coverage to a higher level.
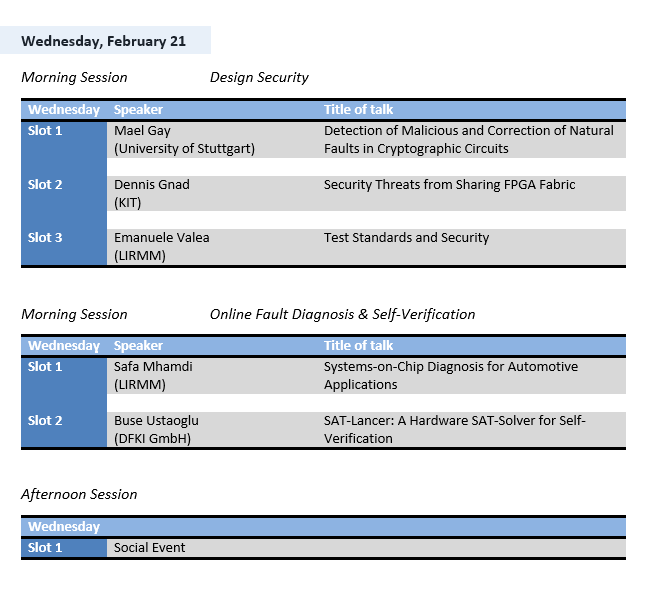
3. Topic: Design Security
Maël Gay (University of Stuttgart)
Detection of Malicious and Correction of Natural Faults in Cryptographic Circuits
Cryptography and its primitives ensure security and safety in the digital domain. As such, cryptographic primitives and implementations are thoroughly analysed on different levels. From theoretical cryptanalysis to side-channel attacks, all possible breaches are studied, and they should remain impervious to attacks.
One common way to recover secret data is fault injection. It is for instance possible to retrieve the secret key from an Advanced Encryption Standard (AES) implementation in only one successful fault injection, through the use of cleverly build equations.
One possible course of actions to avoid such scenario is to use an error detection code. Nevertheless, security oriented codes often have poor error correction capabilities even though their error detection probability is high. On the other hand, linear codes have high error correction capabilities at the cost of error detection. We introduce an architecture providing good error detection and correction capabilities in the form of the Rabii-Keren code.
In the eventuality where one would want to prevent malicious attacks while still being able to correct natural faults, a decision has to be made. We discuss ways to distinguish between malicious and natural errors through the use of our architecture.
Finally, we present an evaluation of the architecture on an FPGA against various fault models, and compare detection and correction capabilities against other codes.
The construction and the evaluation are an ongoing work.
Dennis Gnad (Karlsruhe Institute of Technology)
Security Threats from Sharing FPGA Fabric
New usage scenarios of FPGAs include accelerators in cloud computing or Systems-on-Chip. In both scenarios, users gain software-only access to low-level hardware functionality. For security purposes, logical separation between independent users is essential and feasible. We will show that this is not enough for FPGAs where a joint power distribution network connects all logic. By the freedom given through the FPGA configuration, components can be built to induce high voltage drop to cause faults, and a sensor can be build to detect even minor voltage fluctuations. These components can be considered parts of hardware trojans that can be infiltrated with software, and they enable side-channel and fault attacks that previously were considered to require physical access. As a proof, we will show a Denial-of-Service fault attack, and a CPA side-channel attack on an AES implementation. Finally we will discuss potential further attacks and countermeasures.
Emanuele Valea (LIRMM)
Test Standards and Security
The increasing complexity of integrated circuits leads more and more to the implementation of additional infrastructures which allow the observation of the system activity from the external world. This monitoring capability is essential for reliability purposes (e.g. on-line testing, software updating) and easiness of development (e.g. software debugging, programmable logic configuration). During the last decades the community has been doing big efforts to provide standards for test interfaces that allow virtually complete controllability and observability of the internal resources of the system. Unfortunately the functionality provided by all test standards rises important threats to the integrity of the system: stealing internal secrets, reverse engineering IP cores and tampering the integrated circuits becomes very easy when standard implementations of test interfaces are present. This talk will give a brief description of the threats that involve the most common test standards on traditional circuits (i.e., JTAG, IEEE 1500, IJTAG), it will provide an overview of the countermeasures that have been developed so far by the community, and it will present some perspectives.
Detection of Malicious and Correction of Natural Faults in Cryptographic Circuits
Cryptography and its primitives ensure security and safety in the digital domain. As such, cryptographic primitives and implementations are thoroughly analysed on different levels. From theoretical cryptanalysis to side-channel attacks, all possible breaches are studied, and they should remain impervious to attacks.
One common way to recover secret data is fault injection. It is for instance possible to retrieve the secret key from an Advanced Encryption Standard (AES) implementation in only one successful fault injection, through the use of cleverly build equations.
One possible course of actions to avoid such scenario is to use an error detection code. Nevertheless, security oriented codes often have poor error correction capabilities even though their error detection probability is high. On the other hand, linear codes have high error correction capabilities at the cost of error detection. We introduce an architecture providing good error detection and correction capabilities in the form of the Rabii-Keren code.
In the eventuality where one would want to prevent malicious attacks while still being able to correct natural faults, a decision has to be made. We discuss ways to distinguish between malicious and natural errors through the use of our architecture.
Finally, we present an evaluation of the architecture on an FPGA against various fault models, and compare detection and correction capabilities against other codes.
The construction and the evaluation are an ongoing work.
Dennis Gnad (Karlsruhe Institute of Technology)
Security Threats from Sharing FPGA Fabric
New usage scenarios of FPGAs include accelerators in cloud computing or Systems-on-Chip. In both scenarios, users gain software-only access to low-level hardware functionality. For security purposes, logical separation between independent users is essential and feasible. We will show that this is not enough for FPGAs where a joint power distribution network connects all logic. By the freedom given through the FPGA configuration, components can be built to induce high voltage drop to cause faults, and a sensor can be build to detect even minor voltage fluctuations. These components can be considered parts of hardware trojans that can be infiltrated with software, and they enable side-channel and fault attacks that previously were considered to require physical access. As a proof, we will show a Denial-of-Service fault attack, and a CPA side-channel attack on an AES implementation. Finally we will discuss potential further attacks and countermeasures.
Emanuele Valea (LIRMM)
Test Standards and Security
The increasing complexity of integrated circuits leads more and more to the implementation of additional infrastructures which allow the observation of the system activity from the external world. This monitoring capability is essential for reliability purposes (e.g. on-line testing, software updating) and easiness of development (e.g. software debugging, programmable logic configuration). During the last decades the community has been doing big efforts to provide standards for test interfaces that allow virtually complete controllability and observability of the internal resources of the system. Unfortunately the functionality provided by all test standards rises important threats to the integrity of the system: stealing internal secrets, reverse engineering IP cores and tampering the integrated circuits becomes very easy when standard implementations of test interfaces are present. This talk will give a brief description of the threats that involve the most common test standards on traditional circuits (i.e., JTAG, IEEE 1500, IJTAG), it will provide an overview of the countermeasures that have been developed so far by the community, and it will present some perspectives.
4. Topic: Online Fault Diagnosis & Self-Verification
Safa Mhamdi (LIRMM)
Systems-on-Chip Diagnosis for Automotive Applications
Todays' automotive Electrical and Electronic (E/E) systems are composed of complex Systems-on-Chip (SoCs) that typically consist of independent and heterogeneous blocks, and each block may comprise memory, digital circuits, Analog and Mixed-Signal (AMS) circuits, etc. To fit the automotive standard requirements, SoCs pass through a set of test phases at the end of the manufacturing process. The goal is to achieve zero defective parts per million (DPPM) so as to ensure the quality level required by the standard. Moreover, test is also mandatory during the mission mode of the SoCs. For this purpose, dedicated on-line testing mechanisms are usually embedded into the SoCs, and are combined with repair mechanisms to ensure the reliability of the device during the mission mode. Such failures that occur during the mission mode are the most critical ones as they may result in catastrophic consequences. Thus, in an attempt to identify the source of these failures and avoid their re-occurrence in next generation products, the defective component is always send back to the manufacturer (referred to as "customer returns") who is in charge of analyzing the device to determine the root cause of failure. In this scenario, failures are not easy to reproduce in the laboratory as the real mission conditions and executed workload are unknown and cannot be exhaustively modeled. Therefore, efficient diagnosis schemes to locate and assess failures at different system levels are of vital importance. Diagnosis offers insight about the failing part of the system that needs to be repaired, about the environmental conditions that can jeopardize the system's health, and about corrective actions that should be applied to prevent failure re-occurrence and, thereby, expand the safety features.
The main goal of this Ph.D. thesis is to design and implement a methodology able to identify the source of the failure at SoC-level (e.g. system-level diagnosis), that is, pinpoint the failing sub-systems, IP blocks, and/or interconnections. The inputs required by the system-level diagnosus are the knowledge of the SoC under Diagnosis (SuD) and the test infrastructure already present on-chip to support post-manufacturing testing. Examples of infrastructure to be reused for the purpose of diagnosis are Built-In Self-Test (BIST) and Design-for-Test (DfT) facilities, pattern compression and decompression schemes, on-chip sensors, signal buses, etc. The reusability requires some standardization, which is already observed, for instance, in the shift towards IJTAG or IEEE 1500. When necessary, additional test instruments will be embedded to enhance diagnostic information paying attention that such instruments must be non-intrusive, transparent, and incur a low overhead. For example, the ISO 26262 specifies appropriate measures that must be established to support field monitoring and to collect data. The system design should include the specification of diagnostic features to allow fault identification. The knowledge of all the possible data collected during the mission mode will be exploited to reproduce the environmental conditions experienced by the SoC during failure occurrence.
Buse Ustaoglu (DFKI GmbH)
SAT-Lancer: A Hardware SAT-Solver for Self-Verification
To close the ever widening verification gap, new powerful solutions are strictly required. One such promising approach aims in continuing verification tasks after production of a chip during its lifetime. This approach is called self-verification. However, for realizing self-verification tasks on-chip, verification packages have to be developed.
In this paper, we propose verification package SAT-Lancer. SAT-Lancer is a compact Boolean Satisfiability (SAT) solver and has been implemented entirely on HW with the capability of solving any arbitrary SAT-instance. At the heart of SAT-Lancer is a scalable memory model, which can be adjusted to given memory constraints and allows to store the SAT-instance most effectively. In comparison to previous HW SAT-solvers, SAT-Lancer utilizes significant less area and can handle order of magnitude larger SAT-instances.
Systems-on-Chip Diagnosis for Automotive Applications
Todays' automotive Electrical and Electronic (E/E) systems are composed of complex Systems-on-Chip (SoCs) that typically consist of independent and heterogeneous blocks, and each block may comprise memory, digital circuits, Analog and Mixed-Signal (AMS) circuits, etc. To fit the automotive standard requirements, SoCs pass through a set of test phases at the end of the manufacturing process. The goal is to achieve zero defective parts per million (DPPM) so as to ensure the quality level required by the standard. Moreover, test is also mandatory during the mission mode of the SoCs. For this purpose, dedicated on-line testing mechanisms are usually embedded into the SoCs, and are combined with repair mechanisms to ensure the reliability of the device during the mission mode. Such failures that occur during the mission mode are the most critical ones as they may result in catastrophic consequences. Thus, in an attempt to identify the source of these failures and avoid their re-occurrence in next generation products, the defective component is always send back to the manufacturer (referred to as "customer returns") who is in charge of analyzing the device to determine the root cause of failure. In this scenario, failures are not easy to reproduce in the laboratory as the real mission conditions and executed workload are unknown and cannot be exhaustively modeled. Therefore, efficient diagnosis schemes to locate and assess failures at different system levels are of vital importance. Diagnosis offers insight about the failing part of the system that needs to be repaired, about the environmental conditions that can jeopardize the system's health, and about corrective actions that should be applied to prevent failure re-occurrence and, thereby, expand the safety features.
The main goal of this Ph.D. thesis is to design and implement a methodology able to identify the source of the failure at SoC-level (e.g. system-level diagnosis), that is, pinpoint the failing sub-systems, IP blocks, and/or interconnections. The inputs required by the system-level diagnosus are the knowledge of the SoC under Diagnosis (SuD) and the test infrastructure already present on-chip to support post-manufacturing testing. Examples of infrastructure to be reused for the purpose of diagnosis are Built-In Self-Test (BIST) and Design-for-Test (DfT) facilities, pattern compression and decompression schemes, on-chip sensors, signal buses, etc. The reusability requires some standardization, which is already observed, for instance, in the shift towards IJTAG or IEEE 1500. When necessary, additional test instruments will be embedded to enhance diagnostic information paying attention that such instruments must be non-intrusive, transparent, and incur a low overhead. For example, the ISO 26262 specifies appropriate measures that must be established to support field monitoring and to collect data. The system design should include the specification of diagnostic features to allow fault identification. The knowledge of all the possible data collected during the mission mode will be exploited to reproduce the environmental conditions experienced by the SoC during failure occurrence.
Buse Ustaoglu (DFKI GmbH)
SAT-Lancer: A Hardware SAT-Solver for Self-Verification
To close the ever widening verification gap, new powerful solutions are strictly required. One such promising approach aims in continuing verification tasks after production of a chip during its lifetime. This approach is called self-verification. However, for realizing self-verification tasks on-chip, verification packages have to be developed.
In this paper, we propose verification package SAT-Lancer. SAT-Lancer is a compact Boolean Satisfiability (SAT) solver and has been implemented entirely on HW with the capability of solving any arbitrary SAT-instance. At the heart of SAT-Lancer is a scalable memory model, which can be adjusted to given memory constraints and allows to store the SAT-instance most effectively. In comparison to previous HW SAT-solvers, SAT-Lancer utilizes significant less area and can handle order of magnitude larger SAT-instances.
5. Topic: Design for Reliability & Fault Tolerance
Bastien Deveautour (LIRMM)
Exploring Advantages of Approximate Computing in Logic Hardening
Selecting the ideal trade-off between reliability and cost associated with a fault tolerant architecture generally involves an extensive design space exploration. Employing state of-the-art susceptibility estimation methods makes it unscalable with design complexity. Based on a low computational efforts suceptibility analysis methodologies that helps identifying the most vulnerable circuit elements in order to be hardened, we explore the use of approximate computing circuits to improve the mean time to failure while keeping a low area and power overhead and reduced error probability and error magnitude.
Frank Sill Torres (UFMG)
Sensor-based Detection of Radiation-induced Transient Single-Event Effects
Against the background of nanotechnology, reliability concerns are arising with an alarming pace in current CMOS designs. The shrinking of technology sizes results in circuits that are susceptible to several errors sources like oxide breakdown, parameter variations or radiation. In case of the latter, energetic particle can inject electrical charge into sensitive regions of the semiconductor devices and, thus, lead to transient faults. Until the beginning of the 21st century, studies on this kind of errors focused mostly on memories and application intended for avionics and aerospace environment. In current nanometer technologies though, transient fault resilience is also required for ground level applications and the combinational parts of the circuits. In recent years, several concurrent error detection and/or correction techniques have been proposed to mitigate the effects of transient faults. In contrast to most of the existing approaches, which mainly focus on gate and system level, Bulk Built-In Current Sensors (BBICS) offer a promising solution on transistor level. These sensors are able to detect particle strikes immediately after its occurrence, enabling zero delay penalty and fast error detection.
This talk will focus on radiation based transient faults in previous and current CMOS technologies, related error detection and correction methods, the concept and design strategies of Bulk Built-In Current Sensors as well as its system integration.
Davide Piumatti (Politecnico di Torino)
Identifying functionally untestable faults in microprocessor cores for safety-critical application
The microcontrollers used in safety-critical applications need to achieve strict dependability targets. This requires testing them in several stages of the production process and in the field. The in-field test is very important for detect the presence of faults arising during the life of the microcontroller. When the microcontroller is operating in-field, a not negligible portion of hardware may not be used. A fault in this hardware does not influence the correct functionalities of the microcontroller. Hence, it is necessary to identify and exclude the faults present in the unused hardware (functionally untestable faults) and to remove them from the fault list. In this paper a technique is proposed to identify a subset of the functionally untestable faults.
Exploring Advantages of Approximate Computing in Logic Hardening
Selecting the ideal trade-off between reliability and cost associated with a fault tolerant architecture generally involves an extensive design space exploration. Employing state of-the-art susceptibility estimation methods makes it unscalable with design complexity. Based on a low computational efforts suceptibility analysis methodologies that helps identifying the most vulnerable circuit elements in order to be hardened, we explore the use of approximate computing circuits to improve the mean time to failure while keeping a low area and power overhead and reduced error probability and error magnitude.
Frank Sill Torres (UFMG)
Sensor-based Detection of Radiation-induced Transient Single-Event Effects
Against the background of nanotechnology, reliability concerns are arising with an alarming pace in current CMOS designs. The shrinking of technology sizes results in circuits that are susceptible to several errors sources like oxide breakdown, parameter variations or radiation. In case of the latter, energetic particle can inject electrical charge into sensitive regions of the semiconductor devices and, thus, lead to transient faults. Until the beginning of the 21st century, studies on this kind of errors focused mostly on memories and application intended for avionics and aerospace environment. In current nanometer technologies though, transient fault resilience is also required for ground level applications and the combinational parts of the circuits. In recent years, several concurrent error detection and/or correction techniques have been proposed to mitigate the effects of transient faults. In contrast to most of the existing approaches, which mainly focus on gate and system level, Bulk Built-In Current Sensors (BBICS) offer a promising solution on transistor level. These sensors are able to detect particle strikes immediately after its occurrence, enabling zero delay penalty and fast error detection.
This talk will focus on radiation based transient faults in previous and current CMOS technologies, related error detection and correction methods, the concept and design strategies of Bulk Built-In Current Sensors as well as its system integration.
Davide Piumatti (Politecnico di Torino)
Identifying functionally untestable faults in microprocessor cores for safety-critical application
The microcontrollers used in safety-critical applications need to achieve strict dependability targets. This requires testing them in several stages of the production process and in the field. The in-field test is very important for detect the presence of faults arising during the life of the microcontroller. When the microcontroller is operating in-field, a not negligible portion of hardware may not be used. A fault in this hardware does not influence the correct functionalities of the microcontroller. Hence, it is necessary to identify and exclude the faults present in the unused hardware (functionally untestable faults) and to remove them from the fault list. In this paper a technique is proposed to identify a subset of the functionally untestable faults.
6. Topic: Security in Test & Scan Architecture
Natalia Kaptsova (University of Stuttgart)
Security Quantification for On-Chip Infrastructure
In this talk I will briefly introduce the main research topics that I am currently working on. This presentation motivates and discusses the methods to quantify security in Reconfigurable Scan Networks (RSNs) that are being developed as a part of the SHIVA project. The combinational and high sequential depth of the RSNs poses a big challenge to evaluate and compare different architectures with the same set of segments. Both the internal metrics, which describe the properties of the RSN and the situation of the targeted segment, and the external metrics, which quantify the difficulty to manipulate a segment, must be investigated to evaluate the impact of making the chip infrastructure accessible via the RSNs.
Ahmed Atteya (University of Stuttgart)
Online Prevention of Security Violations in Reconfigurable Scan Networks
Modern systems-on-chip (SoC) designs are requiring more and more infrastructure for validation, debug, volume test as well as in-field maintenance and repair. Reconfigurable scan networks (RSNs), as allowed by IJTAG (IEEE 1687) standard, provide flexible access to the infrastructure with low access latency. However, they can also pose a security threat to the system, through leaking information about the system state. In this talk, a protection method will be presented. It monitors specified security properties online and blocks accesses attempting to violate them. The method prevents unauthorized access to sensitive and secure instruments. In addition, the system integrator can specify more complex security requirements, including giving multiple users different access privileges. Simultaneous accesses to multiple instruments, that would expose sensitive data to an untrusted core (e.g. from 3rd party vendors) or instrument, can be prohibited. The method requires no change to the RSN architecture and is easily integratable with IP core designs. The area overhead with respect to the size of the RSN is below 6% for all benchmarks and scales well with larger networks.
Pascal Raiola (University of Freiburg)
Design of Reconfigurable Scan Networks for Secure Data Transmission
Reconfigurable Scan Networks (RSNs) allow flexible access to embedded instruments for post-silicon validation and debug or diagnosis. However, this scan infrastructure can also be exploited to leak or corrupt critical information as observation and controllability of registers deep inside the circuit are increased. Securing an RSN is mandatory for maintaining safe and secure circuit operations but difficult due to its complex data flow dependencies. This talk presents a method that transforms a given insecure RSN into a secure RSN for which the secure data flow as specified by a user is guaranteed by construction. The presented method is guided by user-defined cost functions that target e.g. test performance or wiring cost. Experimental results demonstrate the applicability of the method to large designs with low runtime.
Rehab Massoud (University of Bremen)
Time-stamps for Hardware Simulation Models Accurate Time-back Annotation
Time-back annotating hardware models can make them more accurate, when it comes to simulation, without compromising their execution time. Extracting the temporal behavior characteristics from the actual executing systems and projecting them back to their models can be more efficient and actual than modeling more architectural details for every contributing factor to the observable behavior. The major obstacle to using time-back annotation from actual systems execution is the limitations in logging cycle accurate traces about the actual executions. In this paper we present how time-stamps can be practically used to obtain cycle accurate temporal logs from fast executing systems.
Security Quantification for On-Chip Infrastructure
In this talk I will briefly introduce the main research topics that I am currently working on. This presentation motivates and discusses the methods to quantify security in Reconfigurable Scan Networks (RSNs) that are being developed as a part of the SHIVA project. The combinational and high sequential depth of the RSNs poses a big challenge to evaluate and compare different architectures with the same set of segments. Both the internal metrics, which describe the properties of the RSN and the situation of the targeted segment, and the external metrics, which quantify the difficulty to manipulate a segment, must be investigated to evaluate the impact of making the chip infrastructure accessible via the RSNs.
Ahmed Atteya (University of Stuttgart)
Online Prevention of Security Violations in Reconfigurable Scan Networks
Modern systems-on-chip (SoC) designs are requiring more and more infrastructure for validation, debug, volume test as well as in-field maintenance and repair. Reconfigurable scan networks (RSNs), as allowed by IJTAG (IEEE 1687) standard, provide flexible access to the infrastructure with low access latency. However, they can also pose a security threat to the system, through leaking information about the system state. In this talk, a protection method will be presented. It monitors specified security properties online and blocks accesses attempting to violate them. The method prevents unauthorized access to sensitive and secure instruments. In addition, the system integrator can specify more complex security requirements, including giving multiple users different access privileges. Simultaneous accesses to multiple instruments, that would expose sensitive data to an untrusted core (e.g. from 3rd party vendors) or instrument, can be prohibited. The method requires no change to the RSN architecture and is easily integratable with IP core designs. The area overhead with respect to the size of the RSN is below 6% for all benchmarks and scales well with larger networks.
Pascal Raiola (University of Freiburg)
Design of Reconfigurable Scan Networks for Secure Data Transmission
Reconfigurable Scan Networks (RSNs) allow flexible access to embedded instruments for post-silicon validation and debug or diagnosis. However, this scan infrastructure can also be exploited to leak or corrupt critical information as observation and controllability of registers deep inside the circuit are increased. Securing an RSN is mandatory for maintaining safe and secure circuit operations but difficult due to its complex data flow dependencies. This talk presents a method that transforms a given insecure RSN into a secure RSN for which the secure data flow as specified by a user is guaranteed by construction. The presented method is guided by user-defined cost functions that target e.g. test performance or wiring cost. Experimental results demonstrate the applicability of the method to large designs with low runtime.
Rehab Massoud (University of Bremen)
Time-stamps for Hardware Simulation Models Accurate Time-back Annotation
Time-back annotating hardware models can make them more accurate, when it comes to simulation, without compromising their execution time. Extracting the temporal behavior characteristics from the actual executing systems and projecting them back to their models can be more efficient and actual than modeling more architectural details for every contributing factor to the observable behavior. The major obstacle to using time-back annotation from actual systems execution is the limitations in logging cycle accurate traces about the actual executions. In this paper we present how time-stamps can be practically used to obtain cycle accurate temporal logs from fast executing systems.
 By plane
By plane
You may reach Kaprun by using the following airports:Salzburg: 100 km
Innsbruck: 150 km
Munich: 210 km
Klagenfurt: 230 km
Vienna/Schwechat: 380 km
To continue the trip to Kaprun with an airport bus:
http://www.postbus.at/en/Airportbus/Airport_bus_Salzburg/index.jsp
To facilitate a problem-free journey, there are also several shuttle service companies offering airport transfers to and from Kaprun.
 By Car
By Car
By car, Zell am See-Kaprun is around 1.5 hours away from Salzburg. Munich is only a 2.5 hours' drive away. Main traffic routes and motorways take you
from both cities to the Zell am See-Kaprun region.Coming from Salzburg, you can choose: either you take the route via the Tauernautobahn motorway through the Salzachtal Valley or via the so-called "Deutsche Eck" route. The drive via the motorway is a bit longer but more comfortable.
The Deutsche Eck route is more impressive. When arriving via the motorway, you must purchase an Austrian Autobahnvignette (motorway badge). The Tauernautobahn motorway will also take you to our region if you arrive from the south. Coming from eastern direction, take the A1 Westautobahn motorway. The German motorway A9 from Munich will take you across the border and in direction Zell am See-Kaprun if you travel from the north.
If you arrive from Innsbruck in the west, take the A12 Inntalautobahn motorway first before exiting at Wörgl. From there, you take the main roads.
Price for a parking space at the hotel: 10,00 € per car and night.
 By Train
By Train
The trains of ÖBB (Austrian Railways) run in regular intervals.Timetable and connections information is available on the Austrian Railways.
Once at Kaprun station, a bus or taxi will take you to the Alpenhaus Kaprun.
 By Taxi
By Taxi
From the airport: price upon request, usually rather expensiveGPS Information:
Address of the Hotel:Das Alpenhaus Kaprun
Schlossstraße 25710 Kaprun
Austria
The package price of
635 EUR
per person includes:- 4 nights in a double room for single use
- 4 x breakfast
- 4 x dinner
- Social Event
- Access to the conference room
- Wifi
The package price of
595 EUR
per person includes:- 4 nights in a double room for double use
- 4 x breakfast
- 4 x dinner
- Social Event
- Access to the conference room
- Wifi
Please fill in the registration document and send it to Kristiane Schmitt by using the following email address:
Kristiane.Schmitt@dfki.de
Note: The local tax of 1.15€ per day is not included in the package price and will be indicated separately.
All other taxes are included.
If you want to send the registration document encrypted, please use this public key (GPG).
(Please ensure that you use S/MIME instead of inline PGP to encrypt the attachment as well.)
For payment by wire transfer:
Note: The local tax of 1.15€ per day is not included in the package price and will be indicated separately.
All other taxes are included.
If you want to send the registration document encrypted, please use this public key (GPG).
(Please ensure that you use S/MIME instead of inline PGP to encrypt the attachment as well.)
For payment by wire transfer:
- Recipient Account: Alpenhaus Kaprun
- SWIFT/BIC: SPAEAT2S (Bankhaus Spaengler Kaprun)
- IBAN: AT12 1953 0100 0001 7451
- Reference: SETS 2018, name of the participant, package price February 19 to 23