MFlops
The following table shows the performance in terms of MFLOPs.The test program is organized in several modules.
| MFLOPs | |||||||
|---|---|---|---|---|---|---|---|
| Module | R10000 | UltraSPARC-II | Pentium-III | Pentium/eg | G3 | R5000 | R12000 |
| 1 | 162 | 188 | 420 | 136 | 94 | 82 | 267 |
| 2 | 86 | 121 | 244 | 227 | 62 | 43 | 148 |
| 3 | 456 | 299 | 506 | 185 | 154 | 179 | 757 |
| 4 | 401 | 260 | 470 | 200 | 107 | 165 | 708 |
| 5 | 345 | 215 | 335 | 266 | 117 | 164 | 553 |
| 6 | 440 | 288 | 471 | 355 | 185 | 165 | 726 |
| 7 | 46 | 53 | 118 | 77 | 32 | 23 | 76 |
| 8 | 435 | 290 | 465 | 397 | 181 | 153 | 706 |
Compile options:
R10000 (250 MHz): -n32 -O3
R12000 (400 MHz): -n32 -O3
UltraSPARC-II (296MHz): -fast -xO4
Pentium-III (dual, 1 GHz): icl -DMSC -O2 -G7 flops.c
Pentium/eg: dual-Pentium-III, 866MHz, compiled with egcs 2.91.66, Flags:
-O3, run under Linux 2.2.14-SMP, 256k Cache, 133 MHz Bus
G3 (MHz):
R5000: same as R10000.
Note: the program is not threaded, so it doesn't make use of any extra CPU's or cores.
Jonathan Leto has made
more benchmarks
with the same program on different PC's.
 The benchmark program I used for the table above is called flops.c,
written by Al Aburto (version 2.0, Dec 1992).
If you want to try the benchmark on your CPU, here's
the source code.
I can't remember where I got it from ...
The benchmark program I used for the table above is called flops.c,
written by Al Aburto (version 2.0, Dec 1992).
If you want to try the benchmark on your CPU, here's
the source code.
I can't remember where I got it from ...
The program was compiled to do 5000000 passes.
Dhrystones
R10000
UltraSPARC-II
Pentium-II
G3
Compiled
(1)
(2)
(3)
(4)
(5)
(6)
Dhrystones
834,724
2,049,180
530,973
520,345
541,711
1,000,000
R10000 250 MHz (IRIX 6.5):
(1) cc -O -n32 dhrystone.c
(2) cc -n32 -O3 -IPA
-OPT:fast_sqrt=ON:alias=restrict:roundoff=3:fast_exp=ON:fast_io=ON -OPT:ptr_opt=ON:unroll_size=1000:unroll_times_max=8 dhrystone.c
UltraSPARC-II 296 MHz: (3) cc -fast dhrystone.c
Pentium-II 233 MHz (BeOS):
(4) gcc -O3 -m486 dhrystone.c
(5) gcc -O3 -m486 -fomit-frame-pointer dhrystone.c (BeOS)
(6) G3 :
Here's the source of the benchmark program
(I think, I got it from wuarchive).
If you want to look at the C code I have used,
here it is.
For any comments, suggestions, results, answers to my questions,
please send me email to
zach tu-clausthal.de !
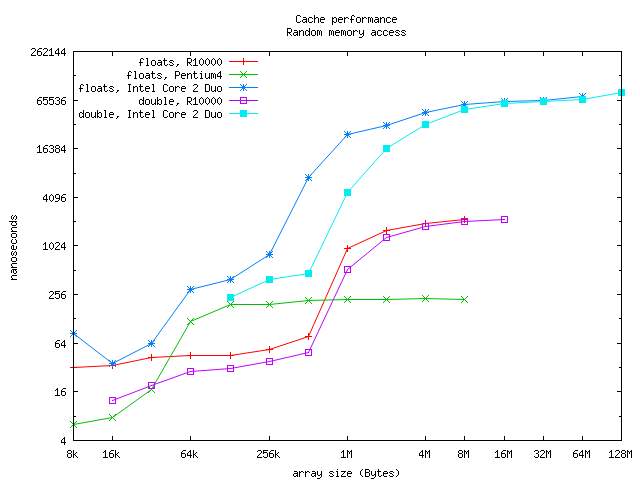
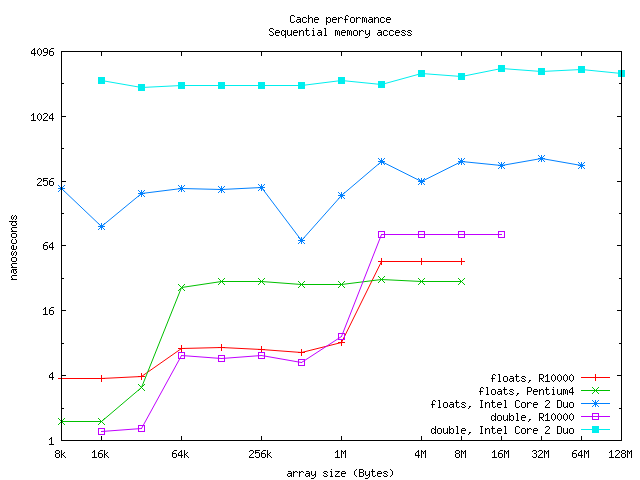
The function f2() is simplyPointer aliasing
The following table shows the performance impact of pointer aliasing
and of double dereferencing (via index arrays):
nanoseconds
compile options
f1
f2
-O2 -n32
950
590
-O3 -n32 -INLINE:must=f1:must=f2
760
340
-O3 -n32 -OPT:alias=restrict
760
340
-O3 -n32 -OPT:alias=restrict -INLINE:must=f1:must=f2
530
220
for ( i = 0; i < 6; i ++ )
d[i] = c[i][0] * e[i] + c[i][1] * e[i] + c[i][2] * e[i];
while f1() is the same except with an index array:
for ( i = 0; i < 6; i ++ )
d[i] = c[i][0] * e[ Bb[i][0] ] + c[i][1] * e[ Bb[i][1] ] + c[i][2] * e[ Bb[i][2] ];
If you would like to have a closer look at the
source or try
it for yourself, here is it!
C++ features
| nanoseconds (user-time) | ||
|---|---|---|
| One operation | code snippet | R10000 (250MHz) |
| static cast | static_cast<Derived*>(base_ptr) | 0.8 |
| dynamic cast (4 levels) | dynamic_cast<Derived4*>(base_ptr) | 1.0 |
| typeid "by hand" | base_ptr->id() != Derived::Id() | 0.95 |
| typeid/RTTI | typeid(*base_ptr)!=typeid(Derived) | 0.90 |
| typeid.before | typeid(*base_ptr).before(typeid(Derived2)) | 0.80 |
Here is the source
of the little benchmark program.